AI tools for computer vision
Related Jobs:
Related Tools:
Ambient.ai
Ambient.ai is an AI-powered physical security software that helps prevent security incidents by detecting threats in real-time, auto-clearing false alarms, and accelerating investigations. The platform uses computer vision intelligence to monitor cameras for suspicious activities, decrease alarms, and enable rapid investigations. Ambient.ai offers rich integration ecosystem, detections for a spectrum of threats, unparalleled operational efficiency, and enterprise-grade privacy to ensure maximum security and efficiency for its users.
Landing AI
Landing AI is a computer vision platform and AI software company that provides a cloud-based platform for building and deploying computer vision applications. The platform includes a library of pre-trained models, a set of tools for data labeling and model training, and a deployment service that allows users to deploy their models to the cloud or edge devices. Landing AI's platform is used by a variety of industries, including automotive, electronics, food and beverage, medical devices, life sciences, agriculture, manufacturing, infrastructure, and pharma.
Datature
Datature is an all-in-one platform for building and deploying computer vision models. It provides tools for data management, annotation, training, and deployment, making it easy to develop and implement computer vision solutions. Datature is used by a variety of industries, including healthcare, retail, manufacturing, and agriculture.
Roboflow
Roboflow is a platform that provides tools for building and deploying computer vision models. It offers a range of features, including data annotation, model training, and deployment. Roboflow is used by over 250,000 engineers to create datasets, train models, and deploy to production.
U-xer
U-xer is an innovative automation tool developed by Quality Museum Software Testing Services. It is designed to meet a broad range of needs, including Robotic Process Automation (RPA), test automation, and bot development. Crafted with user flexibility in mind, U-xer aims to be a user-friendly solution for your automation requirements! U-xer's unique screen recognition models interpret screens in the same way that humans do. This enables non-technical users to automate simple tasks, while allowing advanced users to tackle more complex tasks with ease. With U-xer, you can automate anything, anywhere, whether it's Web or Desktop. U-xer works seamlessly across all platforms with just a screenshot. Unlike other tools, U-xer interprets screens just like a human does, enabling more natural and accurate automation of a wide range of tasks.
Clarifai
Clarifai is a full-stack AI developer platform that provides a range of tools and services for building and deploying AI applications. The platform includes a variety of computer vision, natural language processing, and generative AI models, as well as tools for data preparation, model training, and model deployment. Clarifai is used by a variety of businesses and organizations, including Fortune 500 companies, startups, and government agencies.

Viso Suite
Viso Suite is a no-code computer vision platform that enables users to build, deploy, and scale computer vision applications. It provides a comprehensive set of tools for data collection, annotation, model training, application development, and deployment. Viso Suite is trusted by leading Fortune Global companies and has been used to develop a wide range of computer vision applications, including object detection, image classification, facial recognition, and anomaly detection.
OpenCV
OpenCV is the world's largest computer vision library. It's open source, contains over 2500 algorithms and is operated by the non-profit Open Source Vision Foundation.

OpenCV.ai
OpenCV.ai is a leading provider of computer vision software and services. The company's team of experts has extensive experience in developing optimized large-scale computer vision solutions. OpenCV.ai's expertise is helping businesses grow in a variety of industries, including medicine, manufacturing, and retail. The company's solutions are used by startups and Fortune 500 companies alike.
Roboflow
Roboflow is an AI tool designed for computer vision tasks, offering a platform that allows users to annotate, train, deploy, and perform inference on models. It provides integrations, ecosystem support, and features like notebooks, autodistillation, and supervision. Roboflow caters to various industries such as aerospace, agriculture, healthcare, finance, and more, with a focus on simplifying the development and deployment of computer vision models.
Voxel51
Voxel51 is an AI tool that provides open-source computer vision tools for machine learning. It offers solutions for various industries such as agriculture, aviation, driving, healthcare, manufacturing, retail, robotics, and security. Voxel51's main product, FiftyOne, helps users explore, visualize, and curate visual data to improve model performance and accelerate the development of visual AI applications. The platform is trusted by thousands of users and companies, offering both open-source and enterprise-ready solutions to manage and refine data and models for visual AI.
Restb.ai
Restb.ai is a leading provider of visual insights for real estate companies, utilizing computer vision and AI to analyze property images. The application offers solutions for AVMs, iBuyers, investors, appraisals, inspections, property search, marketing, insurance companies, and more. By providing actionable and unique data at scale, Restb.ai helps improve valuation accuracy, automate manual processes, and enhance property interactions. The platform enables users to leverage visual insights to optimize valuations, automate report quality checks, enhance listings, improve data collection, and more.
EyePop.ai
EyePop.ai is a hassle-free AI vision partner designed for innovators to easily create and own custom AI-powered vision models tailored to their visual data needs. The platform simplifies building AI-powered vision models through a fast, intuitive, and fully guided process without the need for coding or technical expertise. Users can define their target, upload data, train their model, deploy and detect, and iterate and improve to ensure effective AI solutions. EyePop.ai offers pre-trained model library, self-service training platform, and future-ready solutions to help users innovate faster, offer unique solutions, and make real-time decisions effortlessly.
Synthesis AI
Synthesis AI is a synthetic data platform that enables more capable and ethical computer vision AI. It provides on-demand labeled images and videos, photorealistic images, and 3D generative AI to help developers build better models faster. Synthesis AI's products include Synthesis Humans, which allows users to create detailed images and videos of digital humans with rich annotations; Synthesis Scenarios, which enables users to craft complex multi-human simulations across a variety of environments; and a range of applications for industries such as ID verification, automotive, avatar creation, virtual fashion, AI fitness, teleconferencing, visual effects, and security.
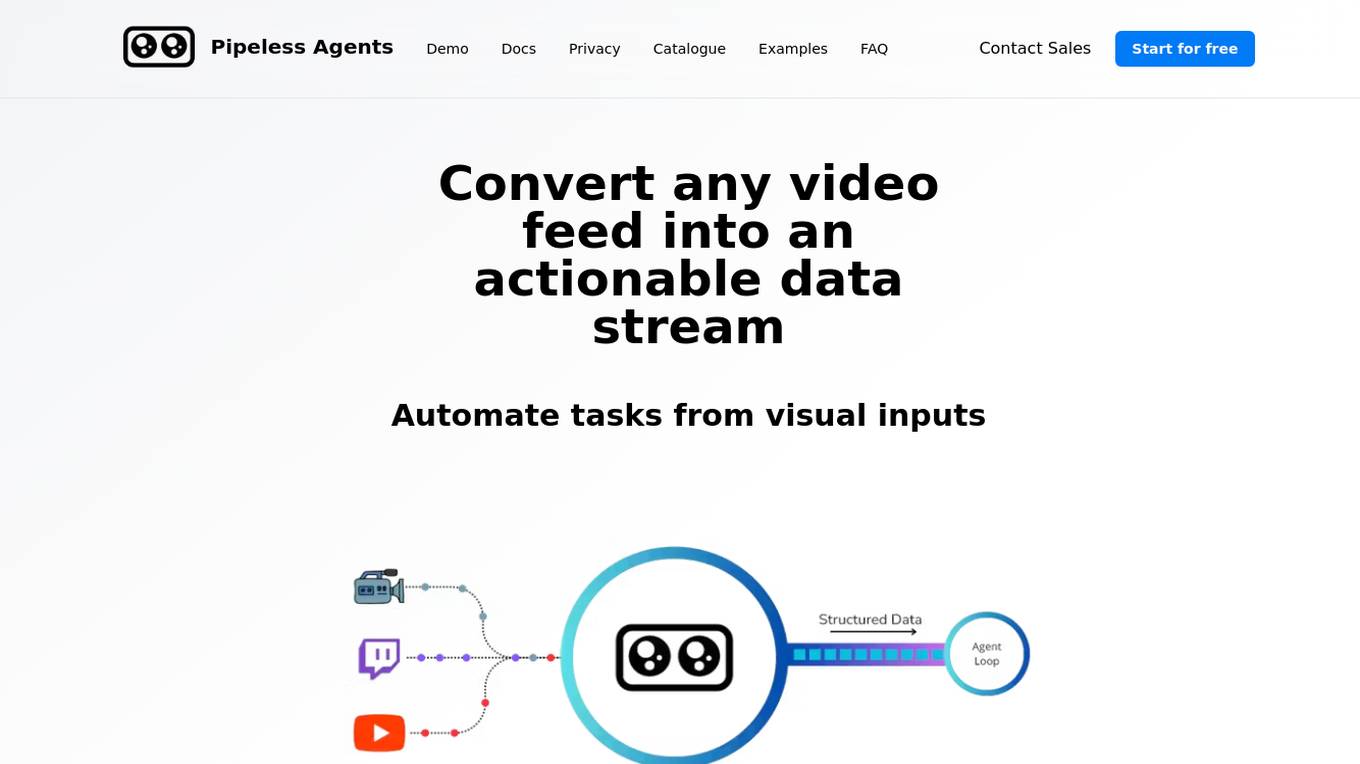
Pipeless Agents
Pipeless Agents is a platform that allows users to convert any video feed into an actionable data stream, enabling automation of tasks based on visual inputs. It serves as a serverless platform for Vision AI, offering the ability to create projects, connect video sources, and customize agents for specific needs. With a focus on simplicity and efficiency, Pipeless Agents empowers users to extract structured data from various video sources and automate processes with minimal coding requirements.
Aiternus
Aiternus is an AI Computer Vision and Data Analysis System that is revolutionizing industries with cutting-edge technology. It offers advanced solutions for various sectors such as manufacturing, construction, logistics, healthcare, retail, sports tech, electronics, and office spaces. Aiternus leverages AI to streamline processes, boost productivity, enhance safety and quality standards, and develop tailor-made solutions for clients' unique needs. The application provides features like work process monitoring, route optimization, AI chatbot support, demand predictions, quality control, performance analysis, and automation of tasks in office spaces.
viAct.ai
viAct.ai is an AI-powered construction management software and app that utilizes computer vision and video analytics to enhance workplace safety. The platform offers scenario-based AI vision technology to simplify monitoring processes, improve productivity, reduce time and cost overruns, and enhance safety measures in the construction industry. viAct.ai provides automated monitoring, PPE detection, environmental monitoring, danger zone alerts, fleet management, and work at height safety solutions. The platform's computer vision technology enables 24/7 remote visual monitoring, real-time smart alerts, and data visualization for better site progress monitoring and performance measurement.
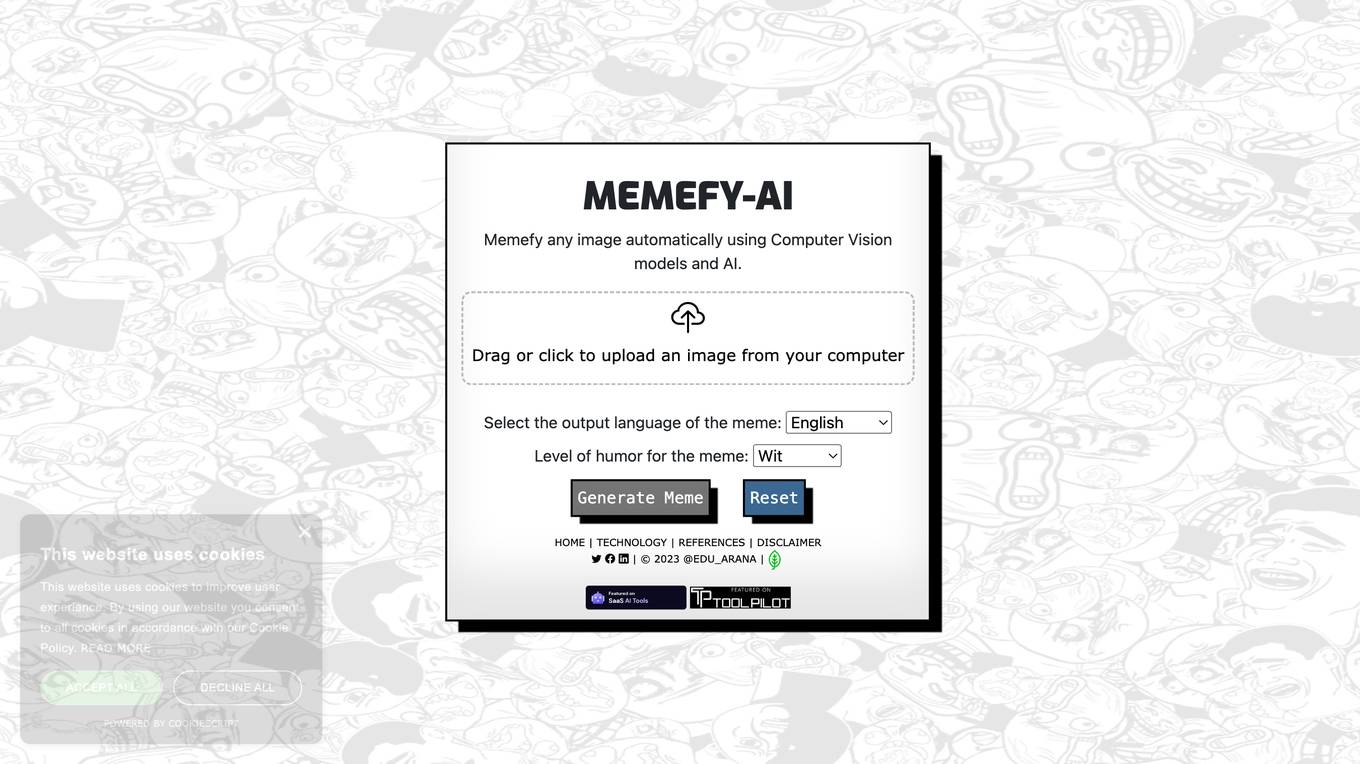
Memefy-AI
Memefy-AI.com is an AI-powered meme generator that utilizes Computer Vision models and AI technology to automatically create memes from uploaded images. Users can drag or click to upload an image from their computer and select various options such as output language and level of humor for the generated meme. The website provides a fun and easy way to create personalized memes with just a few clicks.

SceneXplain
SceneXplain is a cutting-edge AI tool that specializes in generating descriptive captions for images and summarizing videos. It leverages advanced artificial intelligence algorithms to analyze visual content and provide accurate and concise textual descriptions. With SceneXplain, users can easily create engaging captions for their images and obtain quick summaries of lengthy videos. The tool is designed to streamline the process of content creation and enhance the accessibility of visual media for a wide range of applications.
Rerun
Rerun is an SDK, time-series database, and visualizer for temporal and multimodal data. It is used in fields like robotics, spatial computing, 2D/3D simulation, and finance to verify, debug, and explain data. Rerun allows users to log data like tensors, point clouds, and text to create streams, visualize and interact with live and recorded streams, build layouts, customize visualizations, and extend data and UI functionalities. The application provides a composable data model, dynamic schemas, and custom views for enhanced data visualization and analysis.
Pixie: Computer Vision Engineer
Expert in computer vision, deep learning, ready to assist you with 3d and geometric computer vision. https://github.com/kornia/pixie

Counterfeit Detector
Specialist in authenticating products using the latest computer vision technology by Cypheme.

Jimmy madman
This AI is specifically for Computer Vision usage, specifically realated to PCB component identification
Media AI Visionary
Leading AI & Media Expert: In-depth, Ethical, Insightful, developed on OpenAI
Street Sign Recognition GPT
Friendly and professional guide for street sign app development.
Identify movies, dramas, and animations by image
Just send us an image of a scene from a video work and i will guess the name of the work!


mslearn-ai-vision
The 'mslearn-ai-vision' repository contains lab files for Azure AI Vision modules. It provides hands-on exercises and resources for learning about AI vision capabilities on the Azure platform. The labs cover topics such as image recognition, object detection, and image classification using Azure's AI services. By following the lab exercises, users can gain practical experience in building and deploying AI vision solutions in the cloud.
CompressAI-Vision
CompressAI-Vision is a tool that helps you develop, test, and evaluate compression models with standardized tests in the context of compression methods optimized for machine tasks algorithms such as Neural-Network (NN)-based detectors. It currently focuses on two types of pipeline: Video compression for remote inference (`compressai-remote-inference`), which corresponds to the MPEG "Video Coding for Machines" (VCM) activity. Split inference (`compressai-split-inference`), which includes an evaluation framework for compressing intermediate features produced in the context of split models. The software supports all the pipelines considered in the related MPEG activity: "Feature Compression for Machines" (FCM).
vision-agent
AskUI Vision Agent is a powerful automation framework that enables you and AI agents to control your desktop, mobile, and HMI devices and automate tasks. It supports multiple AI models, multi-platform compatibility, and enterprise-ready features. The tool provides support for Windows, Linux, MacOS, Android, and iOS device automation, single-step UI automation commands, in-background automation on Windows machines, flexible model use, and secure deployment of agents in enterprise environments.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.

supervisely
Supervisely is a computer vision platform that provides a range of tools and services for developing and deploying computer vision solutions. It includes a data labeling platform, a model training platform, and a marketplace for computer vision apps. Supervisely is used by a variety of organizations, including Fortune 500 companies, research institutions, and government agencies.

clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.
kornia
Kornia is a differentiable computer vision library for PyTorch. It consists of a set of routines and differentiable modules to solve generic computer vision problems. At its core, the package uses PyTorch as its main backend both for efficiency and to take advantage of the reverse-mode auto-differentiation to define and compute the gradient of complex functions.
PyTorch-Tutorial-2nd
The second edition of "PyTorch Practical Tutorial" was completed after 5 years, 4 years, and 2 years. On the basis of the essence of the first edition, rich and detailed deep learning application cases and reasoning deployment frameworks have been added, so that this book can more systematically cover the knowledge involved in deep learning engineers. As the development of artificial intelligence technology continues to emerge, the second edition of "PyTorch Practical Tutorial" is not the end, but the beginning, opening up new technologies, new fields, and new chapters. I hope to continue learning and making progress in artificial intelligence technology with you in the future.

learnopencv
LearnOpenCV is a repository containing code for Computer Vision, Deep learning, and AI research articles shared on the blog LearnOpenCV.com. It serves as a resource for individuals looking to enhance their expertise in AI through various courses offered by OpenCV. The repository includes a wide range of topics such as image inpainting, instance segmentation, robotics, deep learning models, and more, providing practical implementations and code examples for readers to explore and learn from.
ScreenAgent
ScreenAgent is a project focused on creating an environment for Visual Language Model agents (VLM Agent) to interact with real computer screens. The project includes designing an automatic control process for agents to interact with the environment and complete multi-step tasks. It also involves building the ScreenAgent dataset, which collects screenshots and action sequences for various daily computer tasks. The project provides a controller client code, configuration files, and model training code to enable users to control a desktop with a large model.
landingai-python
The LandingLens Python library contains the LandingLens development library and examples that show how to integrate your app with LandingLens in a variety of scenarios. The library allows users to acquire images from different sources, run inference on computer vision models deployed in LandingLens, and provides examples in Jupyter Notebooks and Python apps for various tasks such as object detection, home automation, satellite image analysis, license plate detection, and streaming video analysis.
hold
This repository contains the code for HOLD, a method that jointly reconstructs hands and objects from monocular videos without assuming a pre-scanned object template. It can reconstruct 3D geometries of novel objects and hands, enabling template-free bimanual hand-object reconstruction, textureless object interaction with hands, and multiple objects interaction with hands. The repository provides instructions to download in-the-wild videos from HOLD, preprocess and train on custom videos, a volumetric rendering framework, a generalized codebase for single and two hand interaction with objects, a viewer to interact with predictions, and code to evaluate and compare with HOLD in HO3D. The repository also includes documentation for setup, training, evaluation, visualization, preprocessing custom sequences, and using HOLD on ARCTIC.

God-Level-AI
A drill of scientific methods, processes, algorithms, and systems to build stories & models. An in-depth learning resource for humans. This repository is designed for individuals aiming to excel in the field of Data and AI, providing video sessions and text content for learning. It caters to those in leadership positions, professionals, and students, emphasizing the need for dedicated effort to achieve excellence in the tech field. The content covers various topics with a focus on practical application.

Q-Bench
Q-Bench is a benchmark for general-purpose foundation models on low-level vision, focusing on multi-modality LLMs performance. It includes three realms for low-level vision: perception, description, and assessment. The benchmark datasets LLVisionQA and LLDescribe are collected for perception and description tasks, with open submission-based evaluation. An abstract evaluation code is provided for assessment using public datasets. The tool can be used with the datasets API for single images and image pairs, allowing for automatic download and usage. Various tasks and evaluations are available for testing MLLMs on low-level vision tasks.

EmbodiedScan
EmbodiedScan is a holistic multi-modal 3D perception suite designed for embodied AI. It introduces a multi-modal, ego-centric 3D perception dataset and benchmark for holistic 3D scene understanding. The dataset includes over 5k scans with 1M ego-centric RGB-D views, 1M language prompts, 160k 3D-oriented boxes spanning 760 categories, and dense semantic occupancy with 80 common categories. The suite includes a baseline framework named Embodied Perceptron, capable of processing multi-modal inputs for 3D perception tasks and language-grounded tasks.

gen-cv
This repository is a rich resource offering examples of synthetic image generation, manipulation, and reasoning using Azure Machine Learning, Computer Vision, OpenAI, and open-source frameworks like Stable Diffusion. It provides practical insights into image processing applications, including content generation, video analysis, avatar creation, and image manipulation with various tools and APIs.
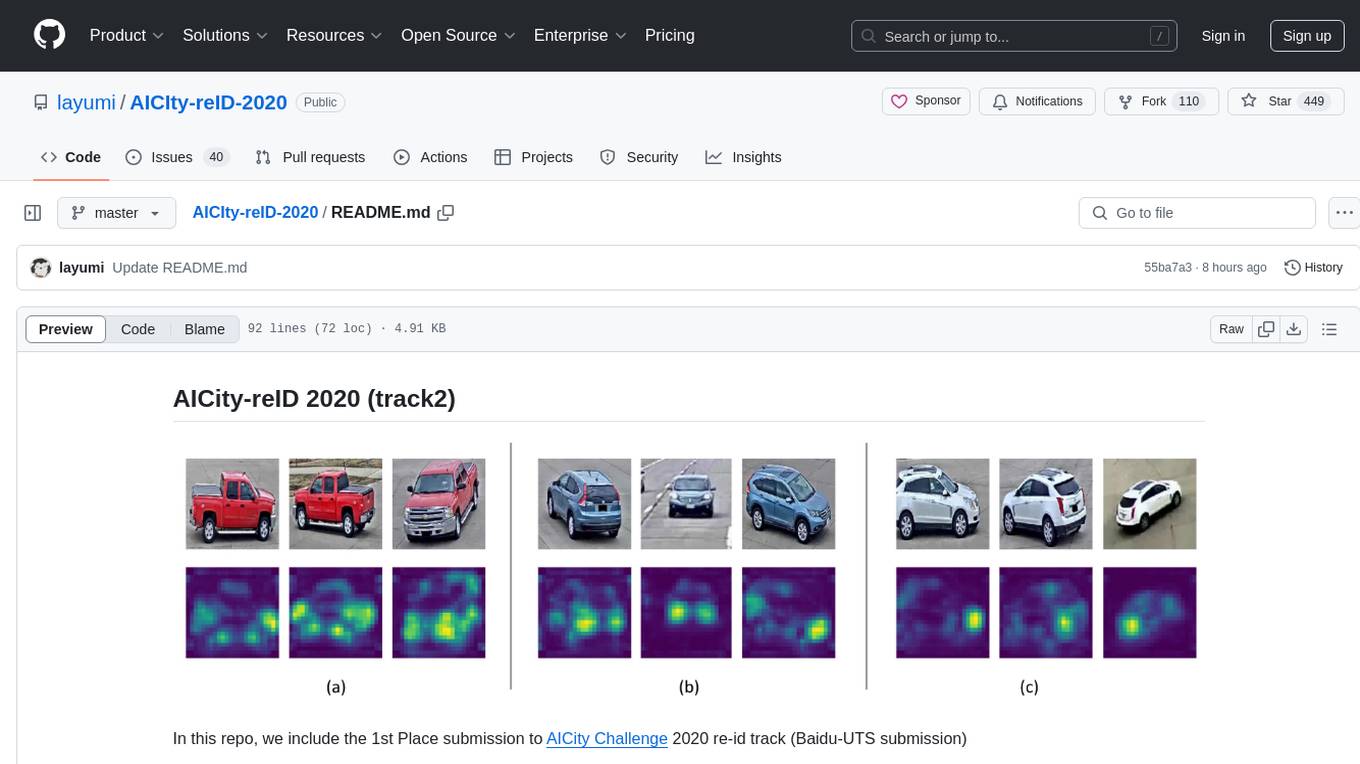
AICIty-reID-2020
AICIty-reID 2020 is a repository containing the 1st Place submission to AICity Challenge 2020 re-id track by Baidu-UTS. It includes models trained on Paddlepaddle and Pytorch, with performance metrics and trained models provided. Users can extract features, perform camera and direction prediction, and access related repositories for drone-based building re-id, vehicle re-ID, person re-ID baseline, and person/vehicle generation. Citations are also provided for research purposes.

GIMP-ML
A.I. for GNU Image Manipulation Program (GIMP-ML) is a repository that provides Python plugins for using computer vision models in GIMP. The code base and models are continuously updated to support newer and more stable functionality. Users can edit images with text, outpaint images, and generate images from text using models like Dalle 2 and Dalle 3. The repository encourages citations using a specific bibtex entry and follows the MIT license for GIMP-ML and the original models.
Dataset
DL3DV-10K is a large-scale dataset of real-world scene-level videos with annotations, covering diverse scenes with different levels of reflection, transparency, and lighting. It includes 10,510 multi-view scenes with 51.2 million frames at 4k resolution, and offers benchmark videos for novel view synthesis (NVS) methods. The dataset is designed to facilitate research in deep learning-based 3D vision and provides valuable insights for future research in NVS and 3D representation learning.